|
Slide 7
Slide
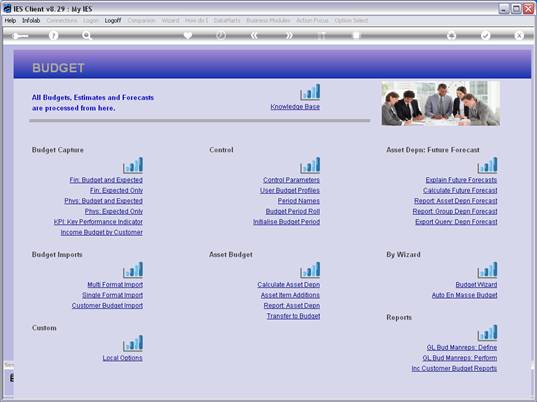
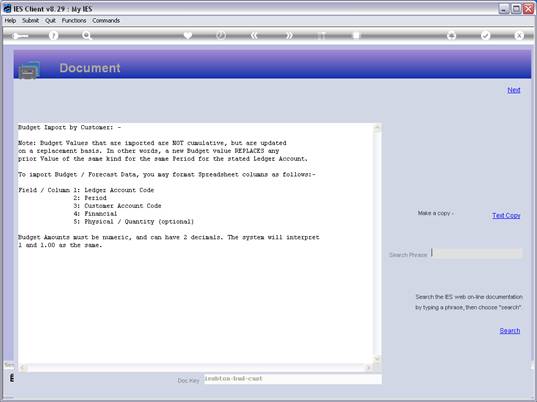
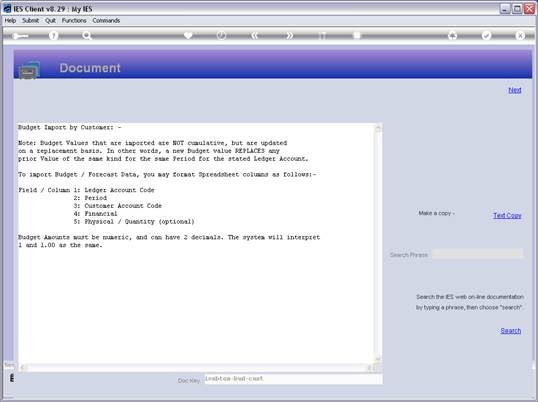
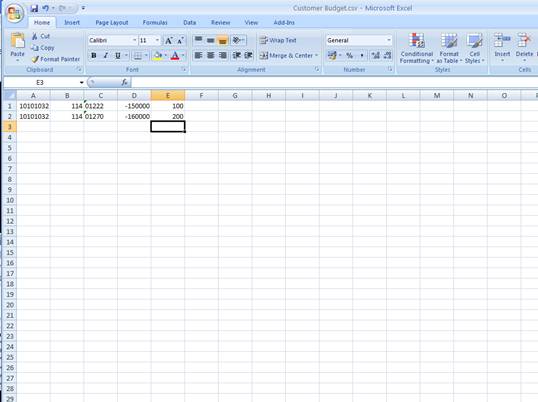
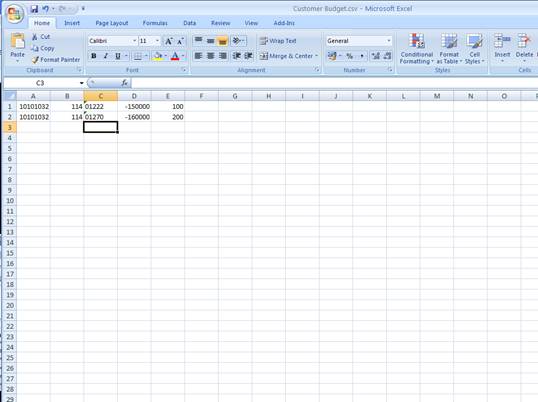
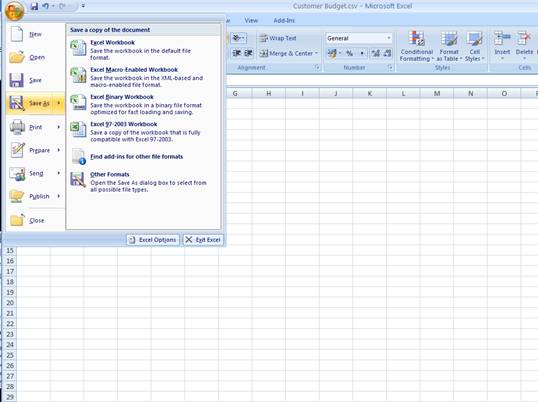
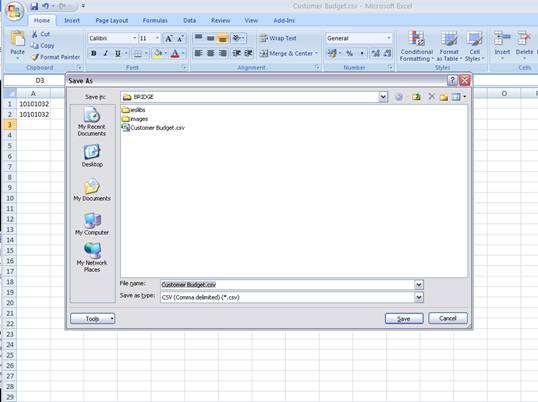
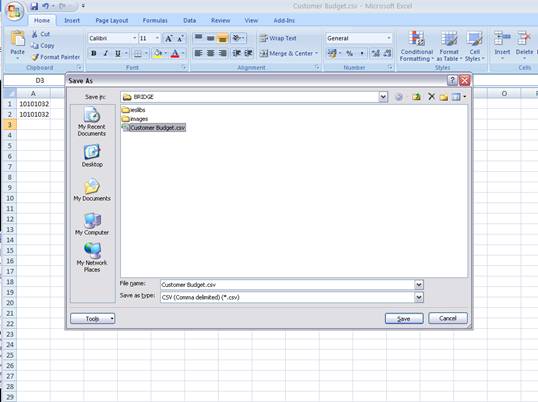
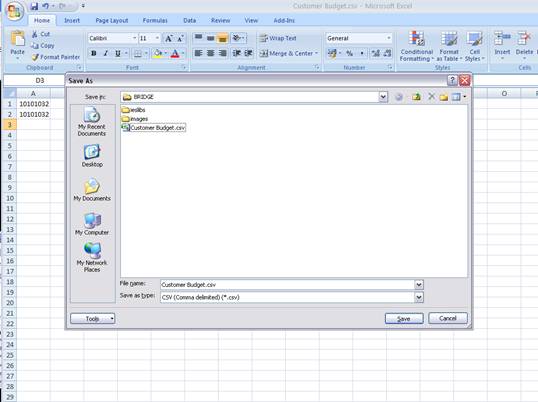
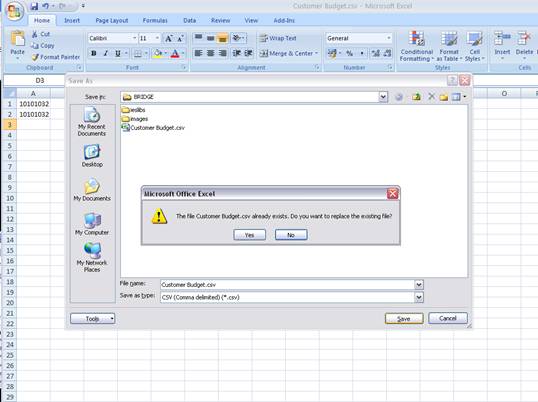
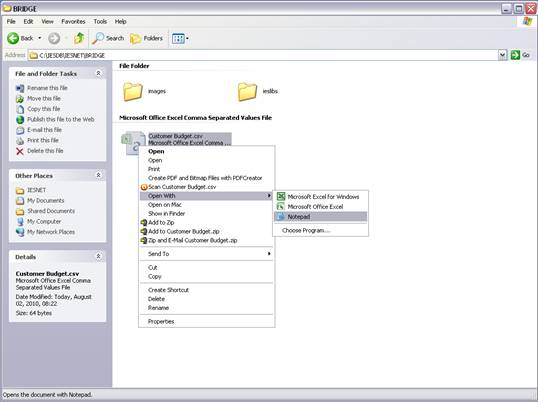
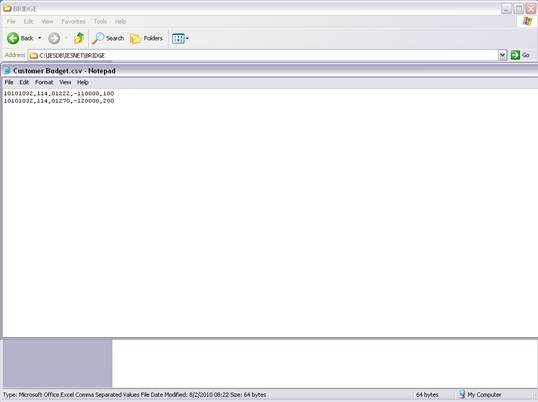
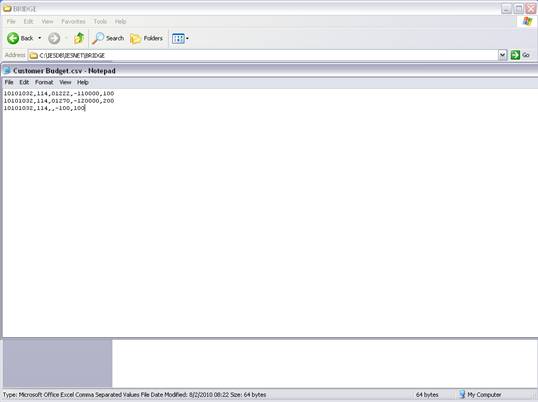
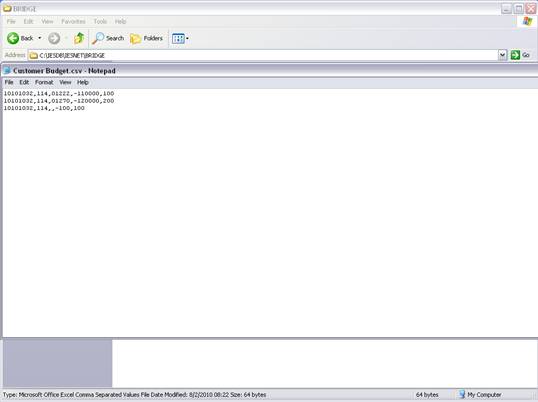
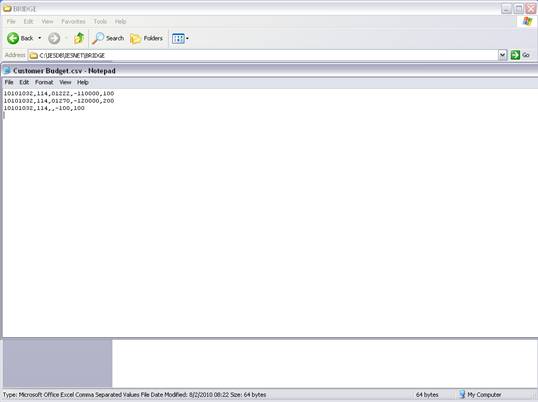
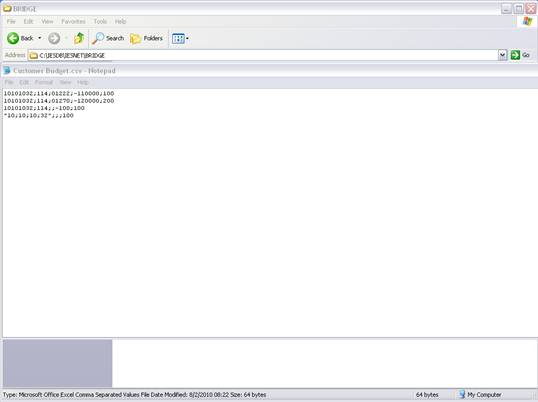
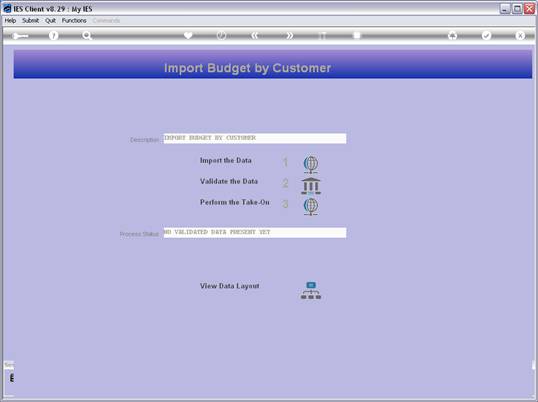
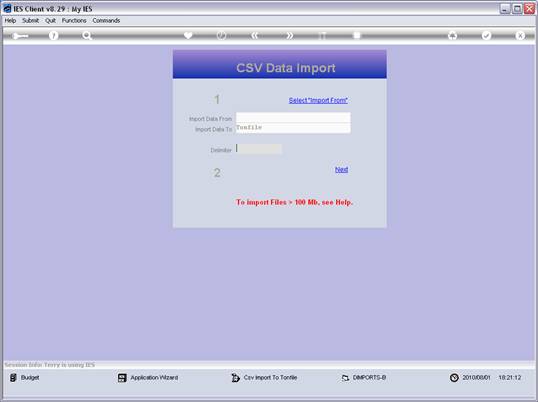
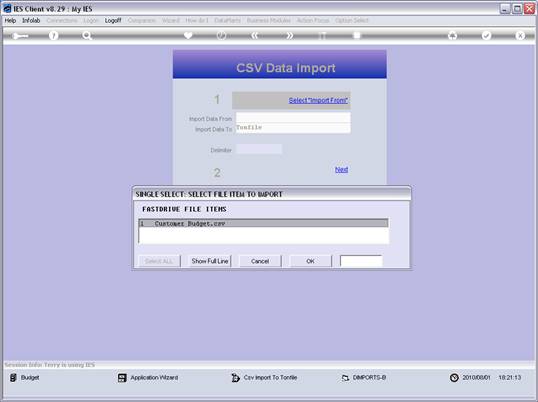
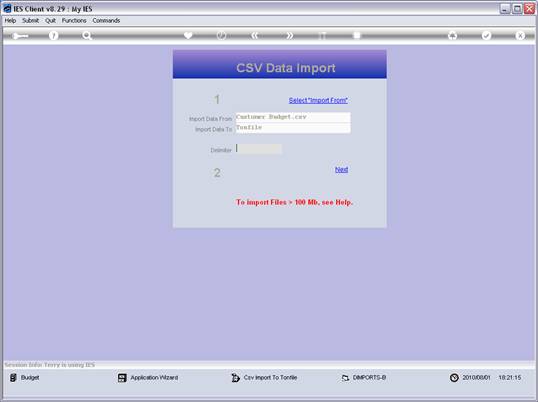
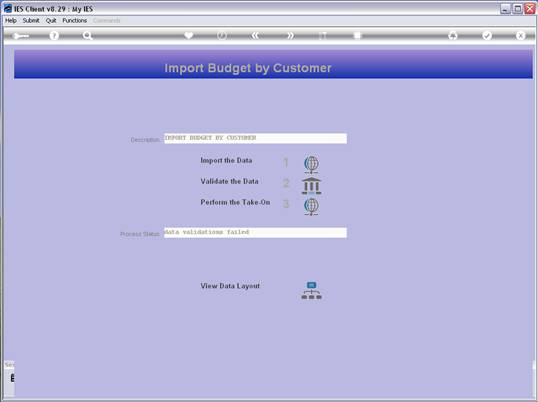
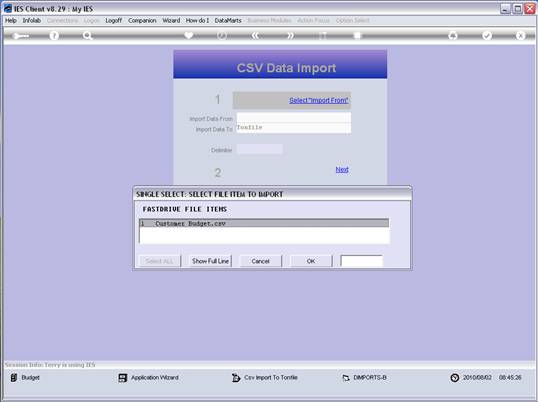
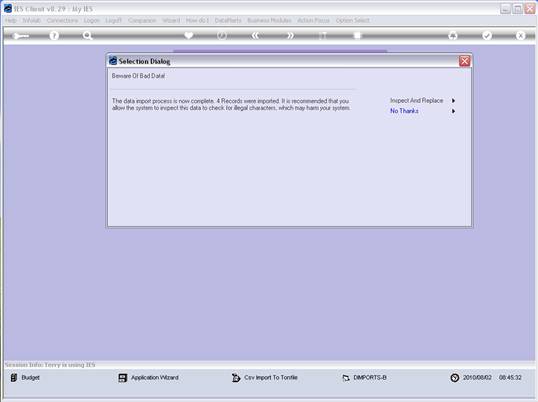
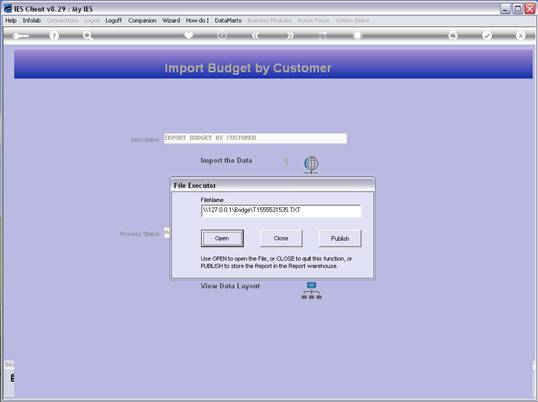
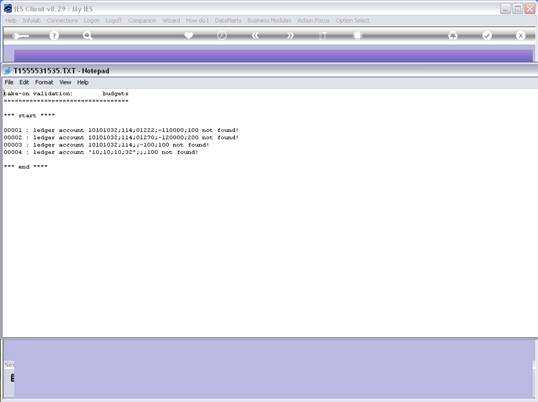
notes: We may note that column C, the 3rd column, is formatted for Text,
because it contains Account Codes that start with a zero, and in the
spreadsheet, if we do not format these cells for a Text field, then the
leading zero will be dropped. This is quite important, because when the
data is validated and the leading zeros are not there, then the system will
reject the Account Codes, because in the system they start with a zero. We
show this principle specifically because many Users have encountered this
situation. So, whenever the values in the system have leading zeros, then
we need to ensure that in the spreadsheet they have them also.
|